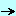|
Migration Unicode Delphi - John COLIBRI. |
- résumé : Delphi 2009 a introduit Unicode comme le type String par Défaut. Cet article présente Unicode, les types String Delphi avant et après Delphi 2009, et présente les instructions qui devront être modifiées pour migrer un
projet Delphi vers les versions 2009 et suivantes
- mots clé : Unicode - Ansi - Oem - Utf-8 - Utf-16 - composites - surrogate - tCharacter - tEncoding
- logiciel utilisé : Windows XP personnel, Delphi 2010
- matériel utilisé : Pentium 2.800 Mhz, 512 Meg de mémoire, 250 Giga disque dur
- champ d'application : Delphi 1 à 5, Delphi 6, Delphi 7, Delphi 2006, Turbo Delphi, Delphi 2007 sur Windows, Delphi 2009, 2010, Delphi XE
- niveau : développeur Delphi
- plan :
1 - Migration vers Delphi 2009, Migration Delphi 2010, Migration Delphi XE Delphi 2009 a introduit une utilisation systématique d'Unicode, au niveau de la librairie, des composants, de l'Interface.
Ce basculement offre des avantages certains: - facilité d'internationalisation des applications
- meilleure adéquation avec Windows
Mais il a aussi introduit des ruptures dans l'évolution d'une version de Delphi
vers la suivante. C'est la première fois qu'un changement de version est "breaking": du code antérieur à Delphi 2009 peut ne pas compiler, ou, une fois compilé, ne pas fonctionner comme escompté
Compte tenu des missions de migration que nous ont confié nos clients, nous pouvons considérer trois cas: - votre code ne comporte pas d'instructions qui sont traitées différemment
avant et après Unicode. Une simple compilation suffit. C'est le cas de 70 % des applications
- votre code utilise des instructions qui ne sont plus correctes en unicode.
En particulier toutes les instructions qui supposent qu'un caractère occupe un octet. Des modifications sont alors à prévoir. Environ 25 % des cas.
- votre code est déjà internationalisé, et utilise les fonctionnalités Unicode
qui étaient disponibles avec les versions Delphi antérieures à Delphi 2009. Il faudra alors changer est adapter toutes ces instructions pour qu'elles fonctionnent correctement sous Delphi 2009 ou suivant. 5 % des cas
Et quand nous parlons de "votre code", il s'agit bien sûr des lignes que vous avez écrites, mais concerne aussi les composants que vous avez sous-traités, achetés, récupérés sur le Web, en source, voire en Open Source.
En résumé
- si, après avoir sauvegardé vos sources, vous les compilez et qu'il passent les tests de validation, bravo, cet article ne vous concerne guère.
- si ce n'est pas le cas, nous vous proposons
- tout d'abord d'expliquer ce qu'est Unicode. Une connaissance minimale est obligatoire, d'autant qu'un jargon particulier a été défini
- nous présenterons alors les types Delphi tels qu'ils existaient avant
Delphi 2009
- suivent les types Unicode Delphi 2009, ainsi que les types maintenus pour des raisons de compatibilité arrière
- puis un descriptif des principaux points à examiner
- et enfin les utilitaires et les stratégies pour effectuer de telles migrations
Bien entendu, nous restons à votre disposition pour assurer les missions de
migrations, qu'elles concernent Unicode, ou d'autres évolutions des vos projets (type base de données ou composant d'accès, architecture légère, Internet, mécaniques de plugin etc)
2 - Définition UNICODE
2.1 - Les caractères sous DOS Sous Dos, nous utilisions tous le jeu de caractères ASCII: 26 lettres minuscules, 26 majuscules, les chiffres, quelques ponctuations: en moins de 127 caractères, tout texte anglais standard pouvait être représenté
- chaque caractère avait un code Ascii: 65 pour le "A", 66 pour le "B", 97 pour le "a", 48 pour le "0" etc
- les 32 premiers codes étaient utilisés pour des caractères "de contrôle": retour chariot, la sonnette etc
Comme l'ensemble tenait en moins de 128 codes, IBM décida d'utiliser les codes restants, entre 128 et 255 pour représenter - la plupart des accents européens
- des caractères "semi-graphiques", comme des barres horizontales ou verticales, pour dessiner des tableaux
- des symboles divers, comme sigma, le trèfle etc
ce qui donna naissance au code OEM :
Toutefois, les pays non latins (les grecs, les arrabes, les russes, sans parler des japonais ou des chinois) souhaitaient utiliser les 128 caractères disponibles pour coder leurs jeux de caractères à eux. De ce fait
- les 128 premiers codes ont été figés par la norme ANSI
- les 128 codes suivants ont été définis par chaque pays. Chaque codification a reçu un numéro appelé code page. Ainsi, les Grecs utilisaient le code
page 737, les Français le code page 850 (OEM Multilingual Latin 1; Western European)
La page Msdn - Code Page Identifiers décrit les différents codes utilisés, et, pour info, en voici quelques uns;
- 737 OEM Greek (formerly 437G); Greek (DOS)
- 850 OEM Multilingual Latin 1; Western European (DOS)
- 855 OEM Cyrillic (primarily Russian)
- 1251 ANSI Cyrillic; Cyrillic (Windows)
- 1252 ANSI Latin 1; Western European (Windows)
- 1253 ANSI Greek; Greek (Windows)
- 1254 ANSI Turkish; Turkish (Windows)
- 1255 ANSI Hebrew; Hebrew (Windows)
- 1256 ANSI Arabic; Arabic (Windows)
Mais, à part quelques tentatives, il n'était pas possible de présenter à l'écran à la fois du cyrillique et de l'hébreu.
2.2 - Unicode Pour permettre l'affichage de TOUS les caractères existant, in the world, plus
quelques autres, la norme UNICODE fut créée: - fondamentalement, chaque caractères se voit attribuer un numéro unique, codé sur 4 octets, appelé code point. Ainsi, la lettre "A" (a majuscule) se
voit attribuer le code $0041, qui est le même pour cette lettre quelle que soit la police de caractère, la taille ou le style :
En revanche, le "a minuscule", "à accent grave", "â circonflexe" etc ont chacun leur propre code point - $00E0 pour "à"
- $00E2 pour "â"
etc Le code est officiellement noté avec un préfixe "U+" suivi de la valeur en hexadécimal
U+0041 - chaque code point a un nom officiel. Pour le A c'est
LATIN CAPITAL LETTER A et pour le "a" (code point U+0061) : LATIN SMALL LETTER A
La page Nom des code points vous donnera une idée des codes et des noms utilisés
Chaque caractère a donc un code point sur 4 octets. Bien sûr, les premiers
codes tiennent sur un octet. Mais certains caractères on besoin de 2 ou plus de 2 octets. Et donc, fondamentallement, le code point est défini sur 4 octets. Et le dessin (appelé script) de chaque caractère est présenté dans des
fichier .PDF, répartis en langue, type de symbole etc.
2.3 - Les catégories de code points Le code Ascii contenait à la fois des lettres et des chiffres, mais aussi des
caractères de contrôle, des semi-graphiques etc. De la même façon, les codes points Unicode ont été classés en 7 catégories fondamentales: Graphic, Format, Control, Private-Use, Surrogate, Noncharacter, Reserved.
Les catégories autres que les lettres étendent Unicode pour écrire des documents scientifiques, des pages de musique, des illustrations symboliques (POLICE OFFICER U+1F46E, PRINCESS U+1F478, RAT U+1F400 !). Plus le Braille, les
dominos, le mahjong, l'alchimie ...
2.4 - Basic Multilingual Plane - BMP La plage des valeurs possibles a été organisée par zones. Des documents précisent ce que contiennent chaque zones, les valeurs utilisées, réservées,
garanties vides etc. La table Code Point Names montre que sur les $FFFF.FFFF valeurs possibles, environ seuls les $0002.FFFF premières valeurs sont utilisées (plus quelques rares valeurs en fin de table).
Pour la plage des 64 K premières valeurs la décomposition se présente ainsi:
Vous constaterez que la plupart des caractères que nous utilisons couramment
(lettres latines et des principaux alphabets) sont au début de la plage des valeurs. Et les codes dont la valeur est inférieure à 64 K est appelé le Basic Multilingual Plane (plan multilingue de base), ou BMP. Les code points que
nous utiliserons couremment seront dans la plage du BMP. Mais il n'en demeure pas moins que les code points sont définis sur 4 octets.
Les autres "plans" dont nous parlerons fort peu, contiennent, par exemple
- le plan 1, Supplementary Multilingual Plane pour les caractères historiques (gothique etc) et musicaux
- le plan 2, Supplementary Ideographic Plane, pour des caractères asiatiques
et ceci a naturellement varié au fil de l'évolution de la norme Unicode. Nous nous limiterons essentiellement au plan 0, BMP.
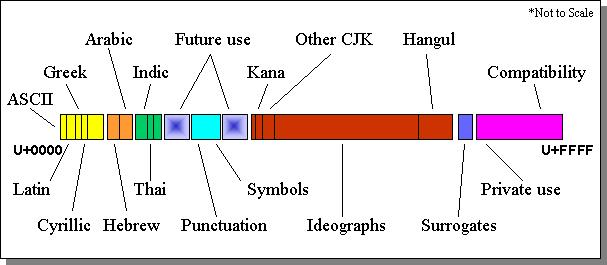
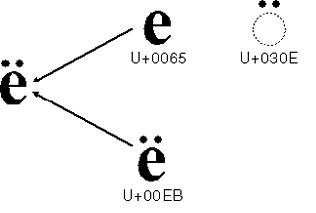
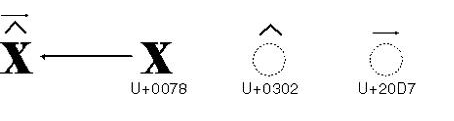
2.5 - Caractères composites
Certains caractères, parmi lesquels nos caractères accentué, ont une double représentation
Ceci peut se représenter ainsi:
Et cela peut se corser avec des compositions multiples: qui est, comme chacun sait, différent de
Le problème se pose alors pour gérer les chaînes contenant ces caractères composites - sont-ils affichés comme un caractère précomposé, ou comme une suite de code points ?
- lorsque nous comparons dex chaînes, U+00E2 est-il égal à 061 0302 ?
Windows a introduit des procédures de normalisation utilisables - pour XP seulement si nous avons installé IDN (Microsoft International Domain
Names Migration API 1.1)
- directement pour Vista, Windows Server 2008 et Windows 7
2.6 - Les représentations compactes Unicode L'utilisation de 4 octets pour représenter chaque caractère a été jugée
excessive. Et de ce fait il a été mis sur pied plusieurs systèmes permettant de compacter le stockage des code points. Les 3 méthodes de codage le plus fréquemment utilisées sont UTF-8, UTF-16 et
UTF-32 (UTF: Unicode Transformation Standard). Il en existe d'autres tels que UCS-2 ou UCS-4 (Universal Character Set), moins utilisées actuellement.
2.6.1 - UTF-8
Dans cette représentation, les code points sont stockés en utilisant 1, 2 ou 4 octets : - les caractères les plus utilisés (les lettres non accentuées) sont codées sur les premiers 7 bits d'un octet.
- au delà de 7 bits, UTF-8 utilise 2 ou 4 octets
Cette représentation - est naturellement plus compacte que les 4 octets des code points
- a l'inconvénient que la ne nombre de caractères d'une chaîne ne peut se
déduire de la taille de la chaîne en octets
- est néanmoins très utilisée pour les pages .HTML et beaucoup de fichiers .XML ou certains protocoles TCP/IP.
2.6.2 - UTF-16
Lorsque la vitesse de traitement est plus importante que la place mémoire, c'est la représentation UTF-16 qui est utilisée Dans cette représentation : - tous les caractères de la BMP (les caractères les plus utilisés) sont codés
sur 2 octets. Ces deux octets sont appelés une code unit
- pour les caractères dépassant un code point de 64 K, et qui ne peuvent donc pas être représentés sur 2 octets, UTF 16 utilise deux "code units". Donc 4
octets aussi. Et ces 4 octets, deux code units sont appelés une surrogate pair (paires de substitution)
Les surrogate pairs sont cantonnées : - dans la plage U+D800 à U+DBFF pour la première code unit ("high surrogate"
ou "leading surrogate")
- et la plage U+DC00 à U+DFFF pour la seconde ("low surrogate")
Cette partie réservée est visible sur l'image présentant le découpage des code points présentée ci dessus. A titre d'exemple
- les valeurs autour de $D840 $DC01 sont des idéogrammes d'extrême orient
- les caractères gothiques, comme la lettre KU sont codés au voisinage de $D800 $DF12
Le format UTF-16 est particulièrement intéressant
- car il correspond au format du système d'exploitation sous-jacent. Il permet donc de meilleures performances lors de l'appel de l'API Windows.
- dans la vaste majorité des cas, les caractères que nous utilisons sont dans
la BMP, et nous n'avons pas besoin de codage sur 2 code units (4 octets)
2.6.3 - UTF-32 UTF-32 utilise 4 octets pour représenter chaque code point
2.6.4 - Quelques Exemples
Un point important est que même si vous avez en mémoire un caractère Unicode, vous le verrez pas nécessairement son image correcte à l'écran. Ansi je n'ai pu apercevoir de symboles gothiques, faute de police Windows sur mon PC.
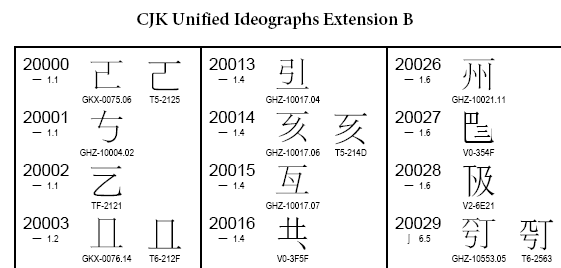
En revanche, j'ai pu afficher: - des caractères chinois, dans la plage des $20000 (CJK Unified Ideographs Extension B). Par exemple
- U+20000, "GKX075" etc
- en UTF-16, surrogate $D840, $DC01
- qui se présente ainsi :
- des caractères grecs:
- un oméga avec des accents
- U+1FA7 : greek small letter omega with dasia and perispomeni and ypojegrammeni
- UTF-16, composite 1F67 0345
- un epsilon avec quelques accents
- U+1F13 greek letter epsilon with dasia and varia
- UTF-16 : composite 1F11 0300
2.6.5 - UCS-2
UCS-2 est toujours codé sur 2 octets, et ne peut représenter que les caractères de la BMP. De plus les "surrogate pairs" de UTF-16 ne sont pas reconnus.
2.6.6 - UCS-4
UCS-4 est toujours codé sur 4 octets, et permet de représenter les mêmes caractères que UTF-32, mais a été supplanté par UTF-32.
2.6.7 - Big Endian, Little Endian - Byte Order Mark - BOM
Pour les représentations utilisant plus de 1 octet, il est aussi possible de préciser dans quel ordre les octets sont organisés: poids le plus faible au début ou à la fin: - en LE, $1234 est stocké $34 $12
- en BE, $1234 est stocké $12 $34
Pour Windows, c'est le mode LE qui est utilisé La spécification de cet ordre est importante pour stocker les données dans des
fichiers. En fait les fichiers peuvent optionnellement comporter une signature, en début de fichier, qui précise cet ordre. Cette signature, et est appellée BOM (Byte Order Mark) et a les valeurs suivantes:
- FF FE : UTF-16, little endian
- FE FF : UTF-16, big endian
- FF FE 00 00 : UTF-32 little endian
- 00 00 FE FF : UTF-32 big endian
- EF BB BF : UTF-8
3 - Les caractères avant Delphi 2009 De Delphi 2 ou 3 à Delphi 2007, nous pouvions utiliser les types suivants: - les caractères Char ont une taille de 1 octet :
- les chaînes compatibles Apple ][, définies par
Var my_string= String[5];
my_string_max: ShortString; // équivalent à | Et
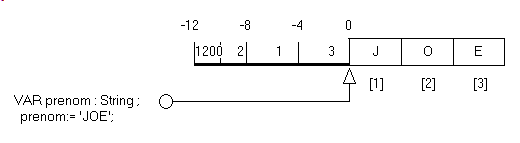
- la taille occupée par la variable est toujours la même, l'octet 0 est utilisé pour gérer la taille actuelle des caractères utilisés ('joe': 3 caractères), le premier indice commence à 1
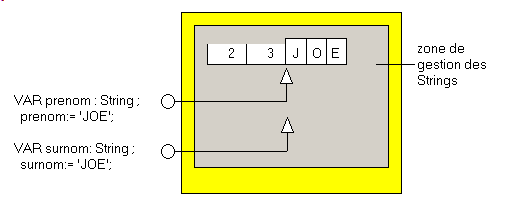
- les chaînes par défaut, de type String, correspondent à AnsiString, ont les propriétés suivantes
- chaque variable est un pointeur vers un prologue suivi des caractères
- elles comportent un prologue avec
- sur 4 octets le nombre de références vers cette valeur
- sur 4 octets la taille, en caractères (donc en octets)
Le schéma est donc le suivant:
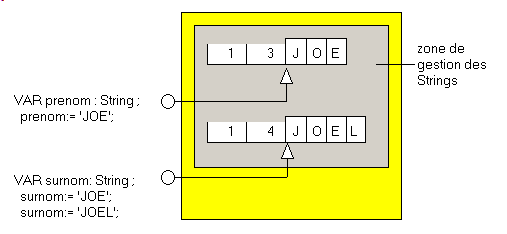
- elle utilise la sémantique "copy on write":
- si plusieurs variables String ont la même valeur, elles pointent vers la même adresse
- si nous modifions la valeur d'une des variables, une copie de la
valeur précédente est effectuées, et la nouvelle zone mémoire est modifiée
Donc, si nous changeons le surnom 'JOE' en 'JOEL' :
- finalement, pour des raisons historiques, le premier caractère à l'indice 1 (et pas 0)
- WideChar sont des caractères Unicode sur 2 octets
- WideString sont des pointeurs de chaînes de caractères Unicode sur 2
octets, compatibles avec le type BSTR COM, donc utilisable pour les appels OLE
- pChar est un pointeur vers un tableau de caractères (Char : 1 octet par caractère).
Lorsque le pChar pointe vers une "StringZ" Windows, la suite des caractères est terminée par un zéro. Mais nous pouvons faire pointer un pChar vers n'importe quoi (c'est un pointeur de type ^Char, avec des fonctionalités de
traitement de chaînes, comme la longueur, utilisables si nous pointons vers une véritable "StringZ", et doté d'une sémantique de pointeur C, donc avec possibilité de recalculer d'adresse par "+") Ce type était à l'origine utilisé
- pour de nombreux appels des API Windows
- pour effectuer de "l'arithmétique des pointeurs" :
- une variable pChar était initialisée pour pointer vers une zone mémoire
- une addition permettait de déplacer le pointeur (si p pointe vers $1234, p +3 pointe vers $1237)
Voici un bout de programme Delphi 6 qui affiche le contenu d'une String:
Type t_delphi_6_string_header=
Packed Record
m_reference_count: LongInt;
m_byte_count: LongInt;
m_bytes: Array[0..0] Of Byte;
End;
t_pt_delphi_6_string_header= ^ t_delphi_6_string_header;
Procedure TForm1.String_Click(Sender: TObject);
Var l_string: String;
l_index: integer;
l_result: String;
Begin
display('String (=AnsiString) avec e aigu et i traema'
l_string:= 'abc éï';
With t_pt_delphi_6_string_header(Integer(l_string)- 8) ^ Do
Begin
display('ref '+ Format('%4x', [m_reference_count]));
display('byte count '+ Format('%4x', [m_byte_count]));
l_result:= '';
For l_index:= 0 To m_byte_count- 1 Do
(*$r-*)
l_result:= l_result+ Format('%1x ', [m_bytes[l_index]]);
(*$r+*)
display(l_result);
End;
End; // String_Click
|
soit (la référence d'usage est -1 car la String est locale) 
Et voici un exemple d'affichage Unicode en Delphi 6
Type t_widestring_delphi_6=
Packed Record
m_byte_length: Integer;
m_bytes: Array[0..0] Of Byte;
End;
t_pt_widestring_delphi_6= ^ t_widestring_delphi_6;
Procedure TForm1.WideString_Click(Sender: TObject);
Const k_u_e_grave= $E8;
k_u_heart= $2665;
Var l_wide_string: WideString;
l_index: Integer;
l_result: String;
Begin
display('WideString e grave, chr(4), e aigu, A');
SetLength(l_wide_string, 5);
l_wide_string[1]:= WideChar(k_u_e_grave);
l_wide_string[2]:= WideChar(k_u_heart);
// -- try surrogates for é
l_wide_string[3]:= WideChar($0065);
l_wide_string[4]:= WideChar($0301);
l_wide_string[5]:= WideChar($0041);
// -- affiche le contenu de la WideString
With t_pt_widestring_delphi_6(Integer(l_wide_string)- 4)^ Do
Begin
display(' byte_count '+ IntToStr(m_byte_length));
display(' Length '+ IntToStr(Length(l_wide_string)));
l_result:= '';
For l_index:= 0 To m_byte_length+ 2- 1 Do
(*$r-*)
l_result:= l_result+ Format('%1x ', [m_bytes[l_index]]);
(*$r+*)
display(' '+ l_result);
End;
End; // widesstring_Click
| et le résultat: 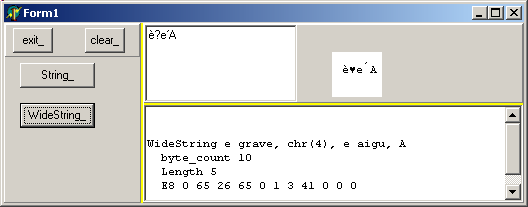
Les librairie d'importation des API Windows (comme WINDOWS.PAS) comportaient en général 3 versions pour chaque procédure ou fonction - une version Unicode avec un suffixe W
- une version Ansi, avec un suffixe A
- une version sans suffixe, qui correspondait exactement à la version Ansi
Par exemple
Function GetModuleHandle(lpModuleName: PChar): HMODULE; Stdcall;
Function GetModuleHandleA(lpModuleName: PAnsiChar): HMODULE; Stdcall;
Function GetModuleHandleW(lpModuleName: PWideChar): HMODULE; Stdcall;
| Dans cet exemple, comme pChar et pAnsiChar sont des alias, la version par défaut est la même que la version Ansi.
Finalement, les types String et WideString sont compatibles en affectation, mais l'affectation d'une WideString à une String peut provoquer une perte d'information.
En résumé, nous constatons donc
- String est l'alias qui désigne le type string préféré, correspondant à AnsiString
- pour AnsiString, 1 caractère = 1 octet
- les WideString sont codés sur 2 octets (ce n'est pas de l'UTF-8 ou de
l'UTF-16, il n'y a pas de surrogates). La RTL nous fournissait de nombreuses procédures pour gérer peu ou prou manuellement Unicode, en particulier vers UTF-8 ou pour la gestion des caractères Multi-Byte. Pour les caractères
utilisant plusieurs Octets (MBCS), les librairies comme SYSUTILS.PAS contenaient des procédures et fonctions spécifiques, comme IsLeadByte.
4 - Les types String Delphi 2009 et suivants 4.1 - Résumé de la gestion des caractères Pour les versions Delphi 2009 et suivantes, l'accent est mis sur Unicode: - pour la partie Unicode
- l'alias String correspond à un une chaîne Unicode codée en UTF-16
- l'alias Char correspond à un caractère Unicode codé sur 2 octets, et correspond au type WideChar
- pChar correspond à un pWideChar
- WideString se comporte comme auparavant, et correspond à une BSTR COM
- le type Usc4Char est un LongInt, correspondant à un code point (4 octets)
- pour la partie Ansi:
- il existe toujours les types AnsiChar et AnsiString, où un caractère occupe un octet, ansi que pAnsiChar qui pointe vers un tableau de caractères Ansi (1 caractères= 1 octet)
- AnsiString gère le code page
- String[nn] ou ShortString gèrent des chaînes de taille mémoire fixe, avec des caractères Ansi sur 1 octet
- les procédures et fonctions des librairies (RTL) contiennent toujours des versions suffixées "W" et "A", mais les versions sans suffixe correspondent à présent à des chaînes Unicode
- des nouvelles unités (CHARACTER.PAS, ANSISTRING.PAS) et de nombreuses procédures ont été ajoutées (dans SYSTEM.PAS et SYSUTILS.PAS) pour faciliter la gestion Unicode et les conversions
4.2 - String et UnicodeString Le type String correspond maintenant à un une chaîne UnicodeString qui est une chaîne Unicode codée en UTF-16 Donc
- les caractères non composites utilisent une "code unit", donc 2 octets
- les caractères composites et les surrogates utilisent 2 "code units", donc 4 octets
4.2.1 - Format mémoire des String (UnicodeString) En mémoire, les chaînes utilisent à présent un prologue de 12 octets: - 2 octets pour le code page
- 2 octets pour la taille de l'élément (appelé "élément size" par Delphi)
- 4 octets pour le compte de référence
- 4 octets pour la le nombre de code units (appelés "élément count" par Delphi)
- le tableau des code units, donc de 2 octets par "élément", indexé à partir de 1
4.2.2 - Longueur de la Chaîne Très important:
- la longueur de la chaîne retournée par Length est le nombre de code units (donc le nombre de mots de 2 octets, ou encore la taille en octets divisée par 2).
- En revanche, le nombre de caractères doit être diminué du nombre de
caractères surrogates et de composites.
- ma_chaîne[indice] retournera la code unit à cette position. Cette valeur sera donc une valeur sur 2 octets, qui PEUT NE PAS pas être un code point
Prenons un premier exemple simple. Nous avons tout d'abord créé une toute petite unité qui nous permet d'analyser le contenu mémoire et disque:
Unit u_display_unicode;
Interface
Uses Classes;
Const k_new_line= #13#10;
Type t_byte_array= Array[0..0] Of Byte;
t_new_string_header=
Packed Record
m_code_page: Word;
m_element_size: Word;
m_reference_count: Longint;
m_element_count: Longint;
m_bytes: t_byte_array;
End;
t_pt_new_string_header= ^t_new_string_header;
Function f_byte_array_to_hex(Var pv_byte_array: t_byte_array;
p_count: Integer): String;
Function f_display_unicode_string(Var pv_unicode_string: String): String;
Function f_display_ansi_string(Var pv_ansi_string: AnsiString): String;
Function f_stream_hex_dump(p_c_stream: tStream): String;
Function f_file_hex_dump(p_file_name: String): String;
Implementation
Uses SysUtils
;
Function f_byte_array_to_hex(Var pv_byte_array: t_byte_array; p_count: Integer): String;
Var l_index: integer;
Begin
Result:= '';
For l_index := 0 To p_count- 1 Do
(*$r-*)
Result:= Result + Format('%1x ', [pv_byte_array[l_index]]);
(*$r+*)
End; // f_byte_array_to_hex
Function f_display_unicode_string(Var pv_unicode_string: String): String;
Begin
With t_pt_new_string_header(Integer(pv_unicode_string)- 12)^ Do
Begin
Result:= ' string : >'+ pv_unicode_string+ '< Length: '
+ IntToStr(Length(pv_unicode_string))+ k_new_line
+ Format(' code page %d', [m_code_page])+ k_new_line
+ Format(' element size %d', [m_element_size]) + k_new_line
+ Format(' ref_count %d', [m_reference_count]) + k_new_line
+ Format(' byte count %d', [m_element_count]) + k_new_line
+ ' bytes $ '+ f_byte_array_to_hex(m_bytes,
m_element_count* m_element_size)
End; // with t_pt_new_string_header^
End; // f_display_unicode_string
Function f_display_ansi_string(Var pv_ansi_string: AnsiString): String;
Begin
With t_pt_new_string_header(Integer(pv_ansi_string)- 12)^ Do
Begin
Result:= ' string : >'+ pv_ansi_string+ '<Length: '
+ IntToStr(Length(pv_ansi_string))+ k_new_line
+ Format(' code page %d', [m_code_page])+ k_new_line
+ Format(' element size %d', [m_element_size]) + k_new_line
+ Format(' ref_count %d', [m_reference_count]) + k_new_line
+ Format(' byte count %d', [m_element_count]) + k_new_line
+ ' bytes $ '+ f_byte_array_to_hex(m_bytes,
m_element_count* m_element_size)
End; // with t_pt_new_string_header^
End; // f_display_ansi_string
Function f_stream_hex_dump(p_c_stream: tStream): String;
Var l_index: integer;
l_byte: Byte;
Begin
Result:= '';
p_c_stream.Position:= 0;
For l_index:= 0 To p_c_stream.Size- 1 Do
Begin
p_c_stream.Read(l_byte, 1);
Result:= Result + Format('%1x ', [l_byte]);
End; // for l_index
End; // f_byte_array_to_hex
Function f_file_hex_dump(p_file_name: String): String;
Var l_c_file_stream: tFileStream;
Begin
l_c_file_stream:= tFileStream.Create(p_file_name, fmOpenRead);
Result:= f_stream_hex_dump(l_c_file_stream);
l_c_file_stream.Free;
End; // f_file_hex_dump
End. // |
Et voici un programme qui manipule des String (donc UnicodeString) - nous avons placés différents contrôles de visualisation
- notre tMemo, en police "Courrier New" pour les explications
- un tRichEdit, une tListbox, un tEdit et un tMemo, qui, par défaut, sont tous en police "Tahoma"
- deux procédures nous permettent d'afficher le contenu de chaînes :
Procedure display(p_text: String);
Begin
Form1.Memo1.Lines.Add(p_text);
End; // display
Procedure do_display(p_string: String);
Var l_index: Integer;
Begin
With Form1 Do
Begin
display('[len='+ IntToStr(Length(p_string))+ '] '+ p_string);
ListBox1.Items.Add(p_string);
RichEdit1.Text:= RichEdit1.Text+ p_string;
Memo2.Lines.Add(p_string);
Edit1.Text:= Edit1.Text+ p_string;
display(p_string+ ' '+ f_display_unicode_string(p_string));
For l_index:= 1 To Length(p_string) Do
display(Format('%2d ', [l_index])+ p_string[l_index]);
End;
End; // do_display
|
- et, à titre d'exemple, un tButton qui affiche la chaîne "abc éî" (e aigu, i circonflexe) :
Procedure TForm1.display_unicode_string_Click(Sender: TObject);
Var l_string: String;
Begin
do_display('abc éî');
End; // display_unicode_string_Click
|
- voici le résultat:
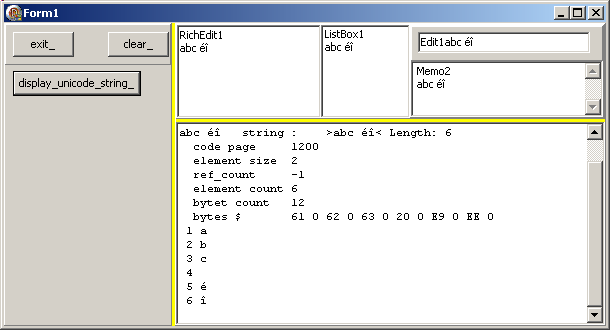
Comme notre chaîne ne comporte que des "code unit"s normaux
- Length est égal au nombre d'éléments
- la taille en octet est égale à 2* Length
- chaque indice retourne bien un caractère à la position attendue
- le code page est de 1200, qui est un code attribué arbitrairement aux
chaînes UnicodeString
Notez aussi que SYSTEM.PAS contient des méthodes qui vous permettent de récupérer les informations du prologue des String :
Function StringElementSize(Const S: UnicodeString): Word; overload; Inline;
Function StringCodePage(Const S: UnicodeString): Word; overload; Inline;
Function StringRefCount(Const S: UnicodeString): Longint; overload; Inline;
|
4.2.3 - Chaînes avec surrogates Les chaînes contenant des surrogates représentent donc des caractères dont le code point est au delà de 64 K. Y figure, par exemple
U+1D6C0 MATHEMATICAL BOLD CAPITAL OMEGA qui est, semble-t-il une sorte d'alias de U+03A9 GREEK CAPITAL LETTER OMEGA Pour afficher ce symbole, nous pouvons utiliser plusieurs techniques:
- appeler une fonction qui convertit le code point en String. Nous utilisons une fonction située dans CHARACTER.PAS:
Type UCS4Char = Type LongWord;
Function ConvertFromUtf32(C: UCS4Char): String; Inline
| et - UCS4Char est défini dans SYSTEM.PAS comme un entier sur 4 octets
- ConvertFromUtf32 convertit le code point en 2 code units
- nous pouvons directement affecter directement #$1D6C0 à une String. Delphi fait automatiquement la conversion
- nous pouvons stocker les deux code units séparément par stocker #$D835#$DEC0
(nous avons trouvé ces deux valeurs par nos routines d'affichage présentées plus haut)
- nous pouvons initialiser la taille de la chaîne à 2 par SetLength et y stocker séparément #$D835 et #$DEC0
Voici le code correspondant:
Var l_string: String;
// 1D6C0 MATHEMATICAL BOLD CAPITAL OMEGA
do_display('omega ConvertFromUtf32 ', ConvertFromUtf32($1D6C0));
do_display('omega #USC4 ', #$1D6C0);
do_display('surrogate ## ', #$D835#$DEC0);
l_string:= #$D835#$DEC0;
do_display('surrogate, via string, # ', l_string);
SetLength(l_string, 2);
l_string[1]:= #$D835;
l_string[2]:= #$DEC0;
do_display('surrogate, via string[n], ', l_string);
// -- the NON SURROGATE omega
do_display('omega, no surrogate, ', #$3A9);
| Et
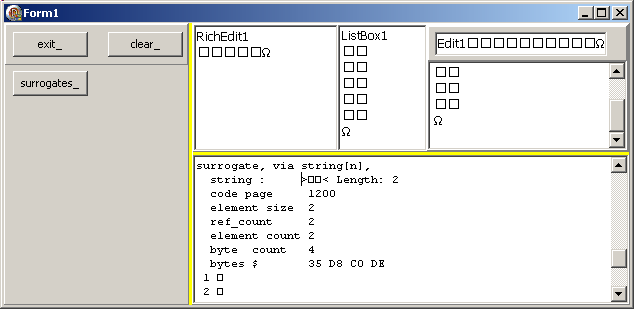 En fait: - les analyse mémoire sont conformes à nos attentes :
- Length retourne le nombre de code units (2), qui est aussi la valeur du
nombre d'éléments
- les deux codes units sont $D835 et $DEC0 (c'est par ce dump que nous les avons trouvées), et, en mémoire, le code est bien stocké en "little endian"
- la taille est 4 octets
- MAIS nous ne voyons pas le "omega" attendu, à part le dernier qui a été affiché par la valeur non-surrogate U+O3A9
La raison est que sur ce PC, l'ancienne mécanique XP n'est pas capable, avec les polices sur mon PC d'afficher le surrogate.
Le même .EXE a été envoyé sur Windows 7 qui est sur le PC que nous avions du acheter fin 2009 pour gérer notre site internet, et voici le résultat : 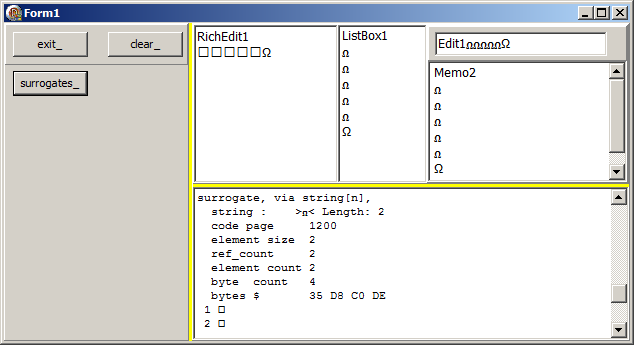 et: - le surrogate oméga apparaît correctement (en Tahoma, et même en Courrier New), sauf dans le tRichEdit, qui ne consent à afficher que le oméga non-surrogate
- nous constatons de plus que le dessin du "omega surrogate mathématique" est légèrement différent du "omega non surrogage"
Pour connaître la le nombre de "glyphes", nous pouvons utiliser (SYSUTILS.PAS):
|
Function ElementToCharLen(Const S: UnicodeString; MaxLen: Integer): Integer; overload
| qui retournera bien 1 pour notre surrogate omega.
Pour le fun, voici l'affichage des surrogates "CJK" présentés plus haut : - le code:
Procedure TForm1.cjk_extension_b_Click(Sender: TObject);
Var l_string: String;
l_index: Integer;
Begin
// 20000 CJK Unified Ideographs Extension B
l_string:= '';
For l_index := 0 To 9 Do
Begin
l_low_surrogate:= $DC00+ l_index;
l_string:= l_string+ #$D840+ Chr(l_low_surrogate);
End;
do_display('10 cjk ', l_string);
End; // cjk_extension_b_Click
| - le résultat (Windows 7):
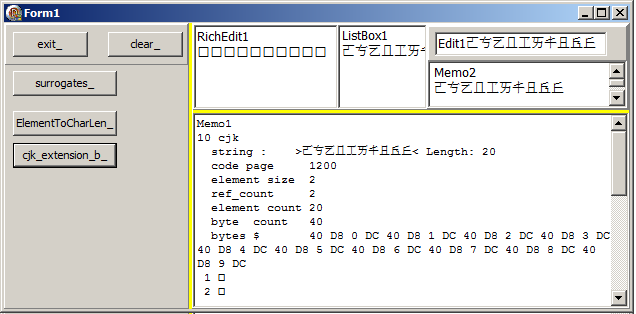
CHARACTER.PAS contient toute une série de fonctions pour tester si un caractère est un surrogate, la partie haute ou basse du surrogate etc.
4.2.4 - Chaînes avec des composites
Rappelons que les composites sont des caractères "assemblés" avec des code points séparés. Par exemple le "e" et l'accent aigu, pour afficher un "é". Voici un projet qui affiche la version composite et la version non composite de
quelques caractères : Nous constatons que : - sur XP, selon les contrôles, l'affichage de composite est plus ou moins réussi
- le même .EXE sous Windows 7 affiche bien, dans notre exemple, les mêmes caractères
Pour les chaînes avec des composites - ElementToCharLen ne calculera PAS le nombre de caractères affichés, mais le nombre de code points. Et pour notre caractère composite, la fonction retournera 2, le nombre de code points
- la RTL ne gère PAS actuellement les caractères composites (pas de version Delphi de NormalizeString).
Sur XP (avec l'API IDN installée) ou Vista, Windows 7, nous pouvons appeler les API Windows directement.
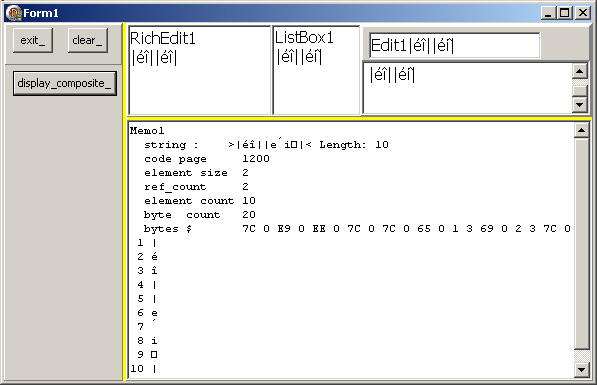
Voici un exemple l'affichage de "é" et "î" en caractère composé ou séparé: - le code:
Var g_string: String= '';
Procedure TForm1.display_composite_Click(Sender: TObject);
Begin
g_string:= '|éî|'+ '|'+ #$0065+ #$0301+ #$0069+#$0302+ '|';
do_display(g_string);
End; // display_composite_Click
|
- le résultat (Windows XP) où vous noterez que le "^" est affiché A COTE du "i":
 - le résultat (Windows 7) où l'affichage de "î" est correct:
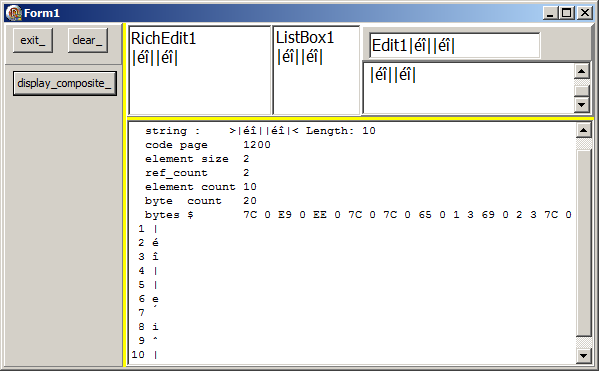
Comme pour les surrogate, - le résultat au niveau de l'affichage dépend donc ici aussi de la version de
Windows (.DLLs de conversions, taille de la police: à titre de comparaison, la .DLL TAHOMA fait environ 340 K sur XP 2003 et plus de 700 K sur Windows 7)
Mentionnons que ces caractères composites sont peu fréquents dans nos textes usuels. Seules les personnes intéressées par traiter les accents séparément du "e" qu'il y a en dessous seront concernées. Bref, très peu de gens.
4.2.5 - Conclusion String (== UnicodeString) UnicodeString offre les avantages suivants : - utilise le comptage de références et la sémantique "copy on write"
- ce type correspond au type de Windows.
4.3 - Char, WideChar Le type Char est un alias de WideChar, et correspond à un caractère Unicode codé sur 2 octets. Il contient donc une seule code unit UTF-16. Un Char ne
peut pas contenir de surrogate (le oméga ou le CFJ extension B). Il peut contenir de composites ("é", soit U+00C9, mais pas #$0065+ #$0301) En gros, le type se comporte comme le WideChar sous les versions antérieures à Delphi 2009.
Un Char est donc toujours une valeur ordinale, qui peut être utilisée dans For, Inc, Dec, High(Char) etc
Pour créer un caractère à partir de son code unit, nous pouvons utiliser :
- la fonction Chr qui accepte un entier, et retourne le caractère (contrairement à ce que dit l'aide, le paramètre n'est pas un Byte mais in Integer)
- l'opérateur #, qui est une abréviation pour Chr
- un surtypage par Char qui provoque la conversion
Var l_caractere: Char;
l_caractere:= Chr($1234);
l_caractere:= #$1234;
l_caractere:= Char($1234);
|
En revanche nous ne pouvons PLUS utiliser un Char dans des ensembles (Set Of), puisque la valeur d'un caractère est codée sur 2 octets, et dépasse donc 255 qui est la limite Pascal pour un élément d'un Set Of. Nous devrons
modifier les instructions utilisant IN.
4.4 - pChar et pWideChar - pChar est un alias pour un pWideChar, et pointe donc sur un tableau de WideChar (2 octets chacun)
4.5 - Usc4Char Ce type correspond à un LongInt pour pouvoir gérer directement des code points. Il est utilisé dans des primitives de conversion code point <-> Utf-16, comme le montre nos exemples précédents
Pour mémoire, UCS4String est défini comme un Array of UCS4Char (Length retourne donc le nombre de caractères Usc4Char).
4.6 - AnsiString
Si nous souhaitons utiliser les anciens types pour lesquels 1 caractère occupe 1 octet, nous pouvons utiliser AnsiString. Le type AnsiString - utilise le même format que les String
- 2 octets pour le code page
- 2 octets pour la taille de l'élément (appelé "élément size" par Delphi)
- 4 octets pour le compte de référence
- 4 octets pour la le nombre de code units (appelés "élément count" par Delphi)
- le tableau des caractères Ansi suit
- naturellement
- le code page détermine à présent le véritable code page Ansi (et pas le code 1200 attribué à Unicode).
- la taille de chaque élément est de 1
- le tableau est un tableau de caractères codés chacun sur 1 octet
Comme le prologue a la même structure, nous utiliserons le même type t_new_string_header pour afficher le contenu mémoire :
- le code pour explorer une AnsiString
Procedure do_display_ansi_string(p_ansi_string: AnsiString);
Var l_index: Integer;
Begin
With Form1 Do
Begin
ListBox1.Items.Add(p_ansi_string);
RichEdit1.Text:= RichEdit1.Text+ p_ansi_string;
Memo2.Lines.Add(p_ansi_string);
Edit1.Text:= Edit1.Text+ p_ansi_string;
display(p_ansi_string+ ' '+ f_display_ansi_string(p_ansi_string));
For l_index:= 1 To Length(p_ansi_string) Do
display(Format('%2d ', [l_index])+ p_ansi_string[l_index]);
End; // with Form1
End; // do_display_ansi_string
Var g_ansi_string: AnsiString;
Procedure TForm1.ansistring_Click(Sender: TObject);
Begin
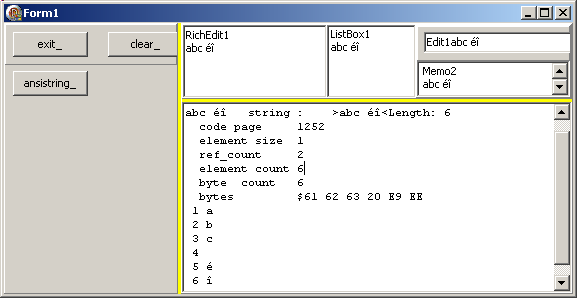
g_ansi_string:= 'abc éî';
do_display_ansi_string(g_ansi_string);
End; // ansistring_Click
|
- et le résultat:
4.6.1 - Code page Par défaut, le code page est celui défini dans le panneau de configuration.
Dans notre cas, c'est le code 1252.
Nous pouvons imposer un autre code page, en le spécifiant comme paramètre de AnsiString: - le code est le suivant:
Type t_cyrillic_string= Type Ansistring(1251);
Procedure TForm1.generate_cyrillic_Click(Sender: TObject);
Var l_cyrillic_string: t_cyrillic_string;
l_index: Integer;
l_string: String;
Begin
l_cyrillic_string:= '';
For l_index := 127+ 65 To 127+ 65+ 7 Do
l_cyrillic_string := l_cyrillic_string + t_cyrillic_string(AnsiChar(l_index));
ListBox1.Items.Add(l_cyrillic_string);
RichEdit1.Text:= RichEdit1.Text+ l_cyrillic_string;
Memo2.Lines.Add(l_cyrillic_string);
Edit1.Text:= Edit1.Text+ l_cyrillic_string;
Memo1.Lines.Add(l_cyrillic_string);
display('');
display(f_display_ansi_string(AnsiString(l_cyrillic_string)));
For l_index:= 1 To Length(l_cyrillic_string) Do
display(
Format('%2d %1x ', [l_index, Ord(l_cyrillic_string[l_index])])
+ l_cyrillic_string[l_index]);
End; // generate_cyrillic_Click
| - et le résultat:
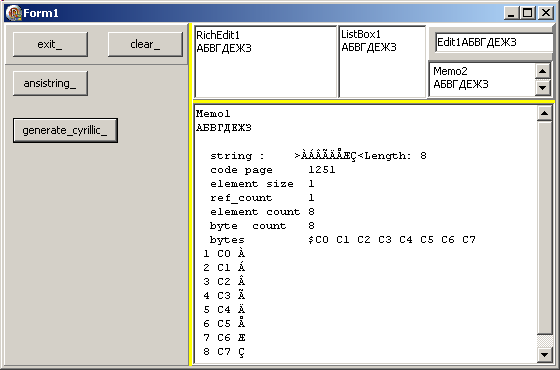
et: - les tables Unicode.Org indiquent que les majuscules cyrilliques commencent à 127+ 65
- notre chaîne cyrillique a été construite. C'est une chaîne de 8 caractères, de 1 octet chacun
- cette chaîne est affichée correctement en cyrillique dans les tMemo, tEdit, tRichEdit, car Delphi effectue une conversion implicite en UTF-16
lorsque nous affectons notre AnsiString aux propriétés Text ou Lines
- notre analyse du contenu de cette AnsiString montre bien les données mémoire attendues (code page 1251, taille de l'élément 1, 8 éléments, et les
codes attendus)
En revanche - l'affichage de la chaîne dans la fonction f_display_ansi_string ne présente pas les caractères escompté: comme le paramètre est un paramètre VAR, la conversion implicite n'a pu avoir lieu
- l'affichage caractère à caractère présente bien le code escompté, mais le caractère affiché n'est pas cyrillique, car l_chaîne_cyrillique[indice] est un AnsiChar et son affichage n'est pas converti en Char
- nous avons du surtyper le paramètre de f_display_ansi_string par AnsiString, sinon le contenu des octets aurait été différent
En fait, pour être être absolument certains que nous affichons les caractères
mémoire, il est plus simple de surtype par des types non String, comme un Byte^, ce qui évite toute conversion implicite. Par exemple, nous pouvons afficher le contenu de la AnsiString par:
Procedure TForm1.display_hex_Click(Sender: TObject);
Var l_cyrillic_string: t_cyrillic_string;
l_index: Integer;
l_pt_byte_array: t_pt_byte_array;
Begin
l_cyrillic_string := '';
For l_index := 127+ 65 To 127+ 65+ 7 Do
l_cyrillic_string:= l_cyrillic_string + t_cyrillic_string(AnsiChar(l_index));
l_pt_byte_array:= t_pt_byte_array(Integer(l_cyrillic_string)- 12);
display(f_byte_array_to_hex(l_pt_byte_array^, 12+ 8));
End; // display_hex_Click
| qui fournit: 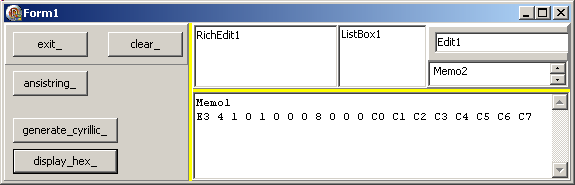
Et si nous souhaitons afficher ou gérer la chaîne cyrillique, il aurait été plus simple de la convertire explicitement par une affectation à une String :
Procedure TForm1.convert_cyrillic_Click(Sender: TObject);
Var l_cyrillic_string: t_cyrillic_string;
l_index: Integer;
l_string: String;
Begin
l_cyrillic_string := '';
For l_index := 127+ 65 To 127+ 65+ 7 Do
l_cyrillic_string:= l_cyrillic_string + t_cyrillic_string(AnsiChar(l_index));
l_string:= l_cyrillic_string;
do_display(l_string);
End; // convert_cyrillic_Click
| qui fournit: 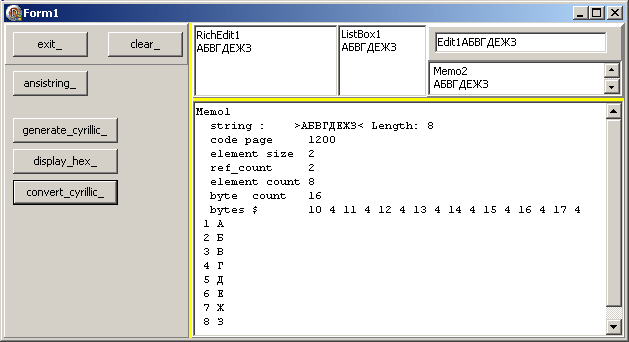 Ici, nous avons construit la chaîne en utilisant un string AnsiString ayant le code page cyrillique, puis l'avons convertie en UnicodeString pour analyse et affichage
Notez que les conversions entre code page peuvent provoquer des pertes d'information. Voici un exemple où nous convertissons entre le code page 437 et 1252:
Type t_ansi_ibm_oem= Type AnsiString(437);
Procedure TForm1.convert_code_page_Click(Sender: TObject);
Var l_save_default_system_codepage: Word;
l_ansi_ibm: t_ansi_ibm_oem;
l_ansi_string: AnsiString;
Begin
display('current default Ansi code page is '+ IntToStr(DefaultSystemCodePage));
display('');
l_save_default_system_codepage:= DefaultSystemCodePage;
DefaultSystemCodePage:= 1252;
l_ansi_ibm:= #$C6;
display('ansi_ibm $C6 :'+ l_ansi_ibm+ Format(' code_page %4d Ord $%2x ',
[ StringCodePage(l_ansi_ibm), Ord(l_ansi_ibm[1])]));
l_ansi_string:= l_ansi_ibm;
display('ansi := ibm :'+ l_ansi_string+ Format(' code_page %4d Ord $%2x ',
[ StringCodePage(l_ansi_string), Ord(l_ansi_string[1])]));
l_ansi_ibm:= l_ansi_string;
display('ibm := ansi :'+ l_ansi_ibm+ Format(' code_page %4d Ord $%2x ',
[ StringCodePage(l_ansi_ibm), Ord(l_ansi_ibm[1])]));
DefaultSystemCodePage:= l_save_default_system_codepage;
End; // ansistring_Click
| et voici le résultat, qui démontre que 437 -> 1252 -> 427 provoque une perte d'information:
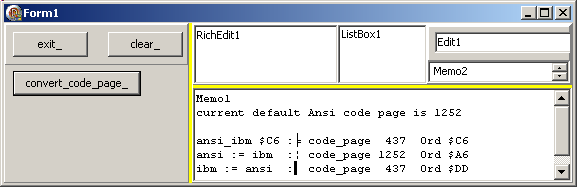
Si nous avions utilisé une chaîne UnicodeString, cela ne serait pas arrivé:
Procedure TForm1.convert_unicode_ansi_Click(Sender: TObject);
Var l_ansi_ibm: t_ansi_ibm_oem;
l_unicode_string: String;
Begin
DefaultSystemCodePage:= 1252;
l_ansi_ibm:= #$C6;
display('ansi_ibm $C6 :'+ l_ansi_ibm + Format(' code_page %4d Ord $%2x ',
[StringCodePage(l_ansi_ibm), Ord(l_ansi_ibm[1])]));
l_unicode_string:= l_ansi_ibm;
display('uni:= ibm :'+ l_unicode_string+ Format(' code_page %4d Ord $%2x ',
[ StringCodePage(l_ansi_ibm), f_utf_16_at(l_unicode_string, 1)]));
l_ansi_ibm:= l_unicode_string;
display('ansi := uni :'+ l_ansi_ibm + Format(' code_page %4d Ord $%2x ',
[StringCodePage(l_ansi_ibm), Ord(l_ansi_ibm[1])]));
End; // convert_unicode_ansi_Click
| et voici le résultat, qui démontre que 437 -> 1252 -> 427 provoque une perte
d'information: 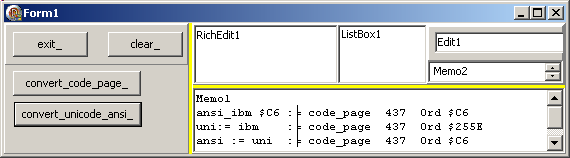
4.6.2 - RawByteString
Delphi a défini un type RawByteString dont le code page initial est $FFFF:
Type RawByteString = Type AnsiString($ffff);
|
Ce type a la propriété de prendre le code page de la chaîne Ansi qui lui est affecté:
Procedure TForm1.raw_byte_string_Click(Sender: TObject);
Var l_ansi_ibm: t_ansi_ibm_oem;
l_ansi_string: AnsiString;
l_raw_byte_string: RawByteString;
Begin
DefaultSystemCodePage := 1252;
l_raw_byte_string:= #$C6;
display('raw:= #$C6 :'+ l_raw_byte_string + Format(' code_page %4d Ord $%2x ',
[StringCodePage(l_raw_byte_string), Ord(l_raw_byte_string[1])]));
l_ansi_ibm := #$C6;
display('ansi_ibm:= $C6 :'+ l_ansi_ibm + Format(' code_page %4d Ord $%2x ',
[StringCodePage(l_ansi_ibm), Ord(l_ansi_ibm[1])]));
l_raw_byte_string:= l_ansi_ibm;
display('raw:= ibm :'+ l_raw_byte_string + Format(' code_page %4d Ord $%2x ',
[StringCodePage(l_raw_byte_string), Ord(l_raw_byte_string[1])]));
l_ansi_string := #$C6;
display('ansi := $C6 :'+ l_ansi_string + Format(' code_page %4d Ord $%2x ',
[StringCodePage(l_ansi_string), Ord(l_ansi_string[1])]));
l_raw_byte_string:= l_ansi_string;
display('raw:= ansi :'+ l_raw_byte_string + Format(' code_page %4d Ord $%2x ',
[StringCodePage(l_raw_byte_string), Ord(l_raw_byte_string[1])]));
End; // raw_byte_string_Click
| et voici le résultat, qui démontre que 437 -> 1252 -> 427 provoque une perte d'information:
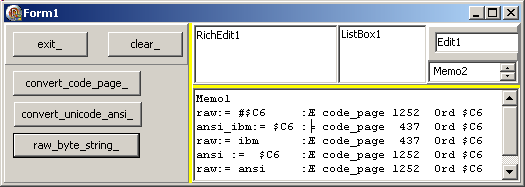
4.6.3 - Utf8String Ce type est défini par
Type UTF8String = Type AnsiString(65001);
|
Une nouvelle unité ANSISTRINGS.PAS contient la plupart des procédures et fonctions que nous utilisions jadis pour manipuler les chaînes Ansi, comportant les noms utilisés avant 2009, ainsi qu'une version spécifiant le préfixe "ansi" explicitement:
Function UpperCase(Const S: AnsiString): AnsiString; overload;
Function CompareStr(Const S1, S2: AnsiString): Integer; overload;
Function AnsiUpperCase(Const S: AnsiString): AnsiString; overload;
Function AnsiCompareStr(Const S1, S2: AnsiString): Integer; Inline; overload;
| Notez que SYSUTILS.PAS comportait aussi des fonctions Ansi_xxx, comme AnsiUpperCase:
Function AnsiUpperCase(Const S: String): String; overload;
| toutefois - les méthodes de SYSUTILS utilisent un paramètre String, et pourront être utilisée sur des String ou des AnsiString (portage plus facile)
- ANSISTRING.AnsiUpperCase en revanche force une valeur AnsiString, et est plus efficace sur les chaînes AnsiString, car elle n'effectue pas de conversion implicite :
4.7 - AnsiChar
Ce type correspond à un caractère sur 1 octet
4.8 - pAnsiChar Ce type correspond à un pointeur ^AnsiChar
4.9 - String[nn] et ShortString
De même les anciens types Pascal String[nn] ou ShortString sont toujours disponibles, et correspondent à des chaînes dont la taille maximale est figée par la déclaration, l'octet 0 contient la taille, et les caractères sont des
caractères Ansi
4.10 - WideString WideString était auparavant utilisé pour les données caractères Unicode. Son format est essentiellement le même qu'un BSTR Windows.
WideString est toujours approprié dans les applications COM.
4.11 - Nouvelles Unités, nouvelles primitives 4.11.1 - WINDOWS.PAS et les autres Api Windows Cette unité contient toujours les versions "A", et "W", mais à présent la
version non suffixée correspond à de String, donc des UnicodeString, ou encore les pointeurs de caractères par défaut sont des pWideChar:
Function GetModuleHandle(lpModuleName: PWideChar): HMODULE; Stdcall;
Function GetModuleHandleA(lpModuleName: PAnsiChar): HMODULE; Stdcall;
Function GetModuleHandleW(lpModuleName: PWideChar): HMODULE; Stdcall;
|
4.11.2 - L'Unité CHARACTER.PAS Cette unité contient de nombreuses procédures et fonctions de gestion des chaînes UnicodeString ansi que des fonctions de conversion (dont nous avons
déjà utilisé quelques unes ci-dessus). Cette unité offre deux versions - une version sous forme de méthode de classe de la classe tCharacter
Type tCharacter=
Class sealed
Public
Class Function ConvertFromUtf32(C: UCS4Char): String; Static;
End; // tCharacter
Var ma_chaine: String;
ma_chaine:= tCharacter.ConvertFromUtf32(#$1D6C0);
| - une version globale.
Function ConvertFromUtf32(C: UCS4Char): String; Inline;
Var ma_chaine: String;
ma_chaine:= ConvertFromUtf32(#$1D6C0);
|
Cette unité comporte des procédure extrèmement importantes pour la gestion des chaînes unicode, comme par exemple (liste partielle): - des fonctions de conversion:
Function ConvertFromUtf32(C: UCS4Char): String; Inline;
Function ConvertToUtf32(Const S: String; Index: Integer): UCS4Char; overload; Inline;
Function ToLower(C: Char): Char; overload; Inline;
Function GetNumericValue(C: Char): Double; overload; Inline
| - des fonctions de test:
Function GetUnicodeCategory(C: Char): TUnicodeCategory; overload; Inline;
Function IsControl(C: Char): Boolean; overload; Inline;
Function IsDigit(C: Char): Boolean; overload; Inline;
Function IsLetter(C: Char): Boolean; overload; Inline;
Function IsLetter(Const S: String; Index: Integer): Boolean; overload; Inline;
Function IsLetterOrDigit(C: Char): Boolean; overload; Inline;
Function IsLetterOrDigit(Const S: String; Index: Integer): Boolean; overload; Inline;
Function IsLower(C: Char): Boolean; overload; Inline;
Function IsLowSurrogate(C: Char): Boolean; overload; Inline;
Function IsNumber(C: Char): Boolean; overload; Inline;
Function IsPunctuation(C: Char): Boolean; overload; Inline;
Function IsSeparator(C: Char): Boolean; overload; Inline;
Function IsSymbol(C: Char): Boolean; overload; Inline;
Function IsWhiteSpace(C: Char): Boolean; overload; Inline;
Function IsUpper(C: Char): Boolean; overload; Inline;
Function IsSurrogate(Surrogate: Char): Boolean; overload; Inline;
Function IsHighSurrogate(C: Char): Boolean; overload; Inline;
|
Nous avons présenté les versions avec un paramètre Char, mais il existe les versions String de ces procédures et fonctions.
4.12 - La Bibliothèque d'exécution (la RTL)
Quelques précisions sur le comportement de la Rtl - tStrings : stocke des UnicodeString en interne (reste déclaré comme string).
- tWideStrings est inchangé et utilise WideString (BSTR) en interne. Est donc
moins efficace que tStrings
- tStringStream
- a été réécrit
- stocke les chaînes en interne avec un encodage ANSI par défaut
- cet encodage peut être changé
- peut être supplanté par tStringBuilder pour la construction de chaînes
- gestion des textes .DFM:
- Delphi 2009 lit toutes les versions de fichiers .DFM précédentes
- le texte pass au format UTF-8 SEULEMENT SI les noms de type des composants, des propriétés ou des composants contiennent des caractères non-ASCII-7
- les chaînes littérales sont codées (comme auparavant) en utilisant #nnn
pour les caractères non-ASCII-7. Par exemple é est stocké come #233
- les valeurs littérales pourraient éventuellement être codées en UTF-8
- le format binaire du .DFM pourrait passer en UTF-8 pour les noms de type
des composants, des propriétés ou des composants
- gestion des textes .PAS
- les sources peuvent rester en ANSI, tant qu'ils ne contiennent pas (identificateur ou chaînes littérales) de caractères qui ne peuvent être
utiliser le code page courant
- l'éditeur gère le BOM. Si vous utilisez un gestionnaire de version, assurez-vous qu'il gère aussi UTF-8 et le BOM
4.13 - Conclusion Pour résumer la situation
- c'est le type UnicodeString, codé en Utf-16 qui est à présent le type String par défaut
- pour ce type, dans l'écrasante majorité des cas, 1 caractère= 2 octets. Les
cas de caractères surrogates ou composite semble plus relever de l'anecdote que de l'industrie. Mais, naturellement, nous pouvons rencontrer ces cas
- les principaux problèmes surviendront plus au niveau des conversions entre
les différents types de caractères où des incompatibilités ou des pertes d'informations pourront survenir
- les autres problèmes provenant de l'utilisation erronnée de pChar au lieu
de pByte relèvent plus de code mal écrit que de problèmes sémantiques
5 - Migration Unicode en Delphi 5.1 - Migrer vers Delphi 2009, 2010, XE
Les explications précédentes montrent que la compilation de projets antérieurs à Delphi 2009 peuvent poser quelques problèmes lorsque nous les compilerons et exécuterons avec les versions Delphi 2009 et suivantes.
Nous pouvons rencontrer des problèmes partout où, par exemple - du code suppose qu'un caractères occupe 1 octet
- des valeurs caractère littérales utilisent un code page précis
- des instructions utilisent des primitives applicables que pour les scalaires dont la valeur ne dépasse pas 255 (Set Of)
Comme la RTL et la VCL ont été entièrement converties un Unicode, il est hélas
impossible de demander au compilateur, par une option, un $IFDEF, une directive, un dialogue de l'IDE, de fonctionner "comme avant". Unicode est enraciné trop profondément dans les librairies pour pouvoir être remplacé à
pied levé pour un projet particulier. Nous sommes donc forcés d'utiliser Unicode. Si votre code n'est pas en porte à faux par rapport aux spécificités Unicode, tout fonctionnera comme avant. C'est, d'après notre expérience, le cas pour
70 % des applications. Dans les autre cas, il faudra - localiser les parties à modifier
- évaluer l'ampleur des modifications à apporter
- adopter une stratégie général de migration
- sélectionner les techniques d'adaptation
Nous allons d'abord - présenter les points isolés qui posent problème
- décrire les stratégies de migrations possibles
5.2 - Les problèmes potentiels
Les points à surveiller - les parties du code qui supposent qu'un caractère occupe 1 octet
- l'utilisation de Set Of Char
- l'utilisation de pChar
- les fichiers et flux
- les conversions implicites et explicites
- les appels de Dll, les interfaces d'unités
5.3 - L'hypothèse 1 caractère= 1 octet Les traitements usuels n'ont pas besoin de faire une hypothèse sur la taille
mémoire des caractères. Les concaténation, insertions, suppressions, indexations, les comparaisons, les fonctions Length, Pos, CompareStr() fonctionnent parfaitement bien quelle que soit la taille. C'est le compilateur
que se préoccupe de ce type de considérations.
En revanche, notre code pouvait utiliser, pour accélérer certains traitements, de primitives qui travaillaient fondamentalement sur des caractères de 1 octet.
En réalité, ces primitives nous viennent de l'Apple ][. Pour fournir un traitement de texte pleine page sur un ordinateur avec 30 K de mémoire, une horloge à 4 KHz et un langage interpréter, pour initialiser le tampon du
traitement de texte, le Pascal UCSD avait introduit la primitive FillChar :
Fillchar(Var pv; p_nombre: Integer; p_valeur: Byte);
| depuis une adresse mémoire (paramètre Var sans type) nous remplissions une zone de taille donnée avec un octet. De façon similaires, nous avions Move
pour déplacer des octets plus rapidement que ne l'aurait fait une boucle For. Nous pouvions utiliser ces primitives sous Delphi 6:
SetLength(g_text, 1000);
FillChar(g_text[1], Length(g_text), ' ');
|
ou encore, pour extraire une chaîne ne contenant que des lettres minuscules (Delphi 6) :
Var g_text: String;
l_start_index, l_index, l_length: Integer;
l_copy_count: Integer;
l_result: String;
l_start_index:= l_index;
While (l_index<= Length(g_text)) And (g_text[l_index] In ['a'..'z']) Do
Inc(l_Index);
l_copy_count:= l_index+ 1- l_start_index;
SetLength(l_result, l_copy_count);
If l_copy_count> 0
Then Move(g_text[l_start_index], l_result[1], l_copy_count);
|
Comme les paramètres "nombre" de FillChar et Move sont des octets, si nous faisons fonctionner ce code sous Delphi 2009 - pour FillChar
- nous n'initialiserons que la moitié du tampon (Length fournit le nombre de code units Utf-16, pas le nombre d'octets
- si nous ajustons Length en multipliant par 2 (ou ElementSize), nous
remplirons bien le tampon, mais avec des octets ' ', donc $32, et chaque code unit contiendra le code unit $3232, ce qui n'est PAS l'espace (il faudrait remplir avec des mots égaux à $0032, ce que ne sait pas faire FillChar)
- la fonction StringOfChar retourne une String remplie avec un caractère donné, et devrait remplacer FillChar pour les String
- pour Move
- les indices, le nombre de code units à copier, la taille finale de la chaîne résultat sont corrects, mais le Move ne copie ici aussi que la moitié des caractères
- si nous multiplions par 2 le nombre d'octets à copier, le résultat sera
ici correct
- en revanche IN sera refusé, parce que les caractères WideString peuvent dépasser 255.
Mentionnons au passage la fonction SizeOf qui retourne la taille en OCTETS
d'un type ou d'une variable. Pour les chaînes Unicode, le résultat ne sera naturellement pas le nombre de caractères. Il faudrait pour cela utiliser Length. Et pour créer une chaîne ayant une longueur donnée, c'est SetLength qu'il faut
utiliser (depuis longtemps déjà), plutôt que GetMem qui ne gère naturellement pas le prologue des String.
En résumé, seul l'emploi de FillChar ou Move devront être examinés de près
lorsque ces primitives sont utilisés sur des String.
5.4 - Utilisation de Set Of Char Ces instructions sont obsolètes, du fait de la limite à 255 des valeurs autorisées à un Set Of.
Si les caractères que nous testons ont un code inférieur à 128 (ou que leur code unit est la même que le code de notre code page), le test fonctionnera. 'A', ou 'é' seront testés correctement. En revanche le test de l'euro ne sera
pas correct, car son code unit est $20AC, alors que sont code ansi est $80:
Procedure TForm1.set_of_char_Click(Sender: TObject);
Type t_set_of_ansi_char= Set Of AnsiChar;
Procedure check(p_text: String; p_char: Char; p_ansi_char: AnsiChar; p_set_of_ansi_char: t_set_of_ansi_char);
Var l_result: String;
Begin
If p_char In p_set_of_ansi_char
Then l_result:= ' ok'
Else l_result:= ' no';
l_result:= Format('%-15s $%2x %4x ', [p_text, Word(p_char), Byte(p_ansi_Char)])+ l_result;
display(l_result);
End; // check
Begin // ansistring_Click
check('A in [''A'', ''B'']', 'A', 'A', ['A', 'B']);
check(' in ['''']', '', '', ['']);
check('é in [''é'']', 'é', 'é', ['é']);
End; // ansistring_Click
| fournira: 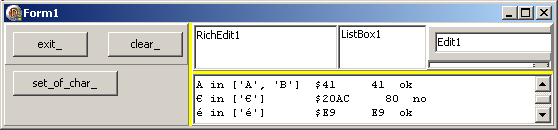
Plusieures solution - utiliser des comparaisons, qui, elles, ne sont pas limitées du tout
- si les tests Set Of sont destinés à un analyseur lexical, la solution est
bien souvent la refonte de la mécanique de test, en utilisant, par exemple
- un automate d'état
- des expressions régulières (pour lesquelles une librairie a été inclue dans Delphi XE)
- utiliser des Set Of AnsiChar
- utiliser des primitives telles que CharInSet :
Type TSysCharSet = Set Of AnsiChar;
Function CharInSet(C: AnsiChar; Const CharSet: TSysCharSet): Boolean;
overload; Inline;
Function CharInSet(C: WideChar; Const CharSet: TSysCharSet): Boolean;
overload; Inline;
| L'aide spécifie que nous ne pouvons pas utiliser tSysCharSet pour créer un
ensemble de caractères Unicode. Et pour cause, la version Unicode convertit le caractère dans sa version Ansi, et compare cette valeur à l'ensemble Set of AnsiChar que vous avez passé en paramètre Voici un exemple:
Procedure TForm1.char_in_set_Click(Sender: TObject);
Procedure check(p_text: String; p_result: Boolean);
Var l_result: String;
Begin
If p_result
Then l_result:= ' OK'
Else l_result:= ' NO';
display(Format('%-30s ', [p_text])+ l_result);
End; // check
Var l_char: Char;
l_ansi_char: AnsiChar;
l_string: String;
l_ansi_string: AnsiString;
Begin // char_in_set_Click
check('CharInSet('''', [''''])', CharInSet('', ['']));
check('l_char:= ''; ''CharInSet(l_char, [''''])', CharInSet(l_char, ['']));
l_ansi_char:= AnsiChar(l_char);
check('l_ansi_char:= AnsiChar(l_char); ''CharInSet(l_ansi_char, [''''])',
CharInSet(l_ansi_char, ['']));
l_string:= '';
l_ansi_string:= l_string;
check('l_string:= ''''; l_ansi_string:= l_string; ''CharInSet(l_ansi_string[1], [''''])',
CharInSet(l_ansi_string[1], ['']));
End; // generate_cyrillic_Click
| dont voici le résultat : 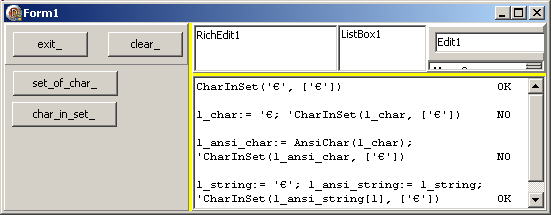 Notez que: - la valeur littérale et la valeur convertie en AnsiString[1] fonctionnent
- l'utilisation d'un paramètre Char échoue : la fonction a une version
avec un paramètre WideChar, et aucune conversion implicite n'est effectuée
- la conversion d'un Char par AnsiChar(mon_char) ne fonctionne pas non plus. En fait, le surtypage par AnsiChar se contente de tronquer la
valeur à 1 octet (l'euro a un unit code de $20AC, AnsiChar(euro) a la valeur $AC, et non pas la valeur $80)
Pour éviter les avertissements, nous pouvons forcer l'utilisation d'AnsiChar:
Var l_set_of_char: Set Of AnsiChar; // pas de warning
l_set_of_char:= ['x', 'y', 'z'];
If AnsiChar('y') In charSet // pas de warning
Then // |
Ces remarques montrent un problème qui nous poursuivra dans toutes ces opérations de migration:
- tout basculer en Unicode peut être plus confortable
- dans certaines circonstances, les caractères Ansi sont impératifs. Reste alors à évaluer et minimiser la pénalité encourrue pour chaque conversion Unicode / Ansi
Il existe aussi une globale LeadBytes qui permettait de tester les valeurs multicaractères MBCS ANSI (test mon_mbcs IN LeadBytes). Ces tests devraient être remplacés par la fonction IsLeadChar.
5.5 - Utilisation de pChar 5.5.1 - Les API Windows Les appels de primitives Windows nécessitant des caractères se font toutes par des pChar (WINDOWS.PAS ne contient aucune String).
Nous avons déjà vu que les API Windows traduites en Delphi ont été adaptées en Unicode (les versions sans "W" sont Unicode, et il existe encore les versions "A" au besoin)
5.5.2 - pChar et arithmétique des pointeurs
En C, les pointeurs permettaient d'accéder aux cellules d'un tableau, et, au lieu d'indexer le tableau, le C utilise un pointeur vers le début du tableau, et incrémente ce pointeur pour visiter les cellules successives. Le compilateur
C tient compte de la taille de la cellule, pour incrémenter le pointeur du nombre d'octets correspondant à la cellule
struct t_compute
{
int total;
float average;
}; t_compute my_compute;
t_compute * my_pt_compute; my_compute= calloc ( ...) ;
my_pt_compute = & my_compute ;
my_pt_compute = my_pt_compute + 3;
|
A cause de cette facilité à désigner n'importe quelle emplacement mémoire en se déplaçant par "+", certains logiciels utilisent beaucoup les pChar. Or, actuellement, il s'agit de pointeurs de WideChar. Et donc toute l'arithmétique
est faussée. La solution est évidente: - utiliser des tampons d'octets et non plus des pChar
- éviter ce type d'arithmétique
5.5.3 - POINTERMATH
Il existe bien directive $POINTERMATH ON qui autorise le compilateur à incrémenter un pointeur typé quelconque:
Procedure TForm1.pointermath_Click(Sender: TObject);
Var l_integer_array: Array Of Integer;
l_pt_integer: ^Integer;
Begin
SetLength(l_integer_array, 3);
l_integer_array[0]:= $11111111;
l_integer_array[1]:= $22222222;
l_integer_array[2]:= $33333333;
(*$Pointermath On*)
l_pt_integer:= @ l_integer_array[0];
display(IntToHex(l_pt_integer^, 4));
Inc(l_pt_integer);
display(IntToHex(l_pt_integer^, 4));
l_pt_integer:= l_pt_integer+ 1;
display(IntToHex(l_pt_integer^, 4));
(*$Pointermath Off*)
// -- not accepted outside $POINTERMATH l_pt_integer:= l_pt_integer+ 1;
End;
|
Dans notre exemple, l'incrémentation de 1 augmente l'adresse du pointeur de la taille de la cellule, ici 4 octets. Pour les nostalgiques de l'arithmétique des pChar, l'unité SYSTEM.PAS définit
{$POINTERMATH ON}
pByte = ^Byte;
{$POINTERMATH OFF}
| Nous préférons néanmoins utiliser des pointeurs vers des types bien définis, et, au besoin, utiliser des calculs d'adresse, comme nous l'avons fait pour
analyser le contenu mémoire dans les exemples ci-dessus.
5.6 - Les fichiers et les flux Les fichiers peuvent comporter une signature BOM précisant le type de caractère utilisé.
Delphi propose plusieurs primitives pour écrire ou lire cette signature
Tout d'abord, les fonctions tStrings.SaveToFile et tStrings.LoadFromFile on un paramètre optionnel de type tEncoding.
tEncoding - utilise par défaut le code page du panneau de configuration Windows
- supporte UTF-8
- supporte UTF-16, en big et little endian
- supporte l'écriture et la lecture du BOM
- peut être utilisé comme ancêtre pour des code page personnalisés
Voici un petit projet qui écrit et lit un chaîne 'A'+ #$0045+ #$0301+ 'Z' en utilisant les 4 types de codages possibles:
Procedure TForm1.save_to_file_Click(Sender: TObject);
Var l_encoding: String;
l_save_file_name: String;
Begin
With encoding_listbox_ Do
l_encoding:= Items[ItemIndex];
l_save_file_name:= ExtractFilePath(Application.ExeName)+ '\'+ l_encoding+ '.txt';
With TStringList.Create Do
Begin
Text:= 'A'+ #$0045+ #$0301+ 'Z';
If l_encoding= 'ASCII'
Then SaveToFile(l_save_file_name, TEncoding.ASCII) Else
If l_encoding= 'UTF-8'
Then SaveToFile(l_save_file_name, TEncoding.UTF8) Else
If l_encoding= 'UTF-16 LE'
Then SaveToFile(l_save_file_name, TEncoding.Unicode) Else
If l_encoding= 'UTF-16 BE'
Then SaveToFile(l_save_file_name, TEncoding.BigEndianUnicode);
display(Format('%-10s ', [l_encoding])+ f_file_hex_dump(l_save_file_name));
Free;
End; // with TStringList
End; // save_to_file_Click
| et voici le résultat : 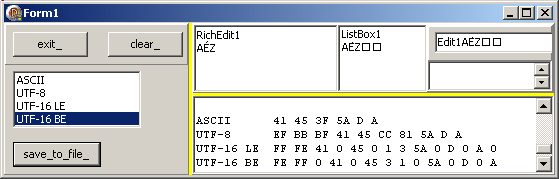
Les nouvelles classes tStreamWrite, tStreamReader ont aussi un paramètre tEncoding.
Notez que : - nous utilisons éventuellement le paramètre tEncoding pour écrire, mais nous
abstenons en général de le spécifier pour la lecture: Delphi lira la signature, et adaptera la lecture à la signature.
- lors d'une migration, il faudra décider si nous continuons à utiliser un
fichier text sans BOM, ou si nous ajoutons, lors de la migration, la signature BOM aux fichiers existants. Parmi les critères, le plus important est l'utilisation des fichiers par d'autres logiciels qui ne gèrent
éventuellement pas la signature BOM, ou que nous ne pouvons ou souhaitons pas adapter.
Les anciennes primitives Write / Writeln ainsi que Read / et Readln
- sont toujours utilisable pour lire ou écrire des caractères depuis le périphérique par défaut
- tiennent compte du code page ANSI/OEM
- sont essentiellement utilisée pour les applications en mode CONSOLE, qui
emploie surtout les caractères ANSI et OEM
- les lectures et écritures de fichier utilisant ces primitives transfèrent des caractères ANSI / OEM, même si le nom du fichier est WideChar
5.7 - Conversions implicites et explicites 5.7.1 - Conversions Implicites Les différents types de chaînes sont compatibles en affectation. Nous pouvons donc utiliser n'importe quel type, et Delphi effectuera les conversions imposée
par la syntaxe. La simple affectation, ou un appel de procédure permet donc de provoquer la conversion. Rappelons que - l'affectation de chaînes Unicode à des chaînes Ansi peut provoquer une perte
d'information (la conversion inverse ne restitue pas les valeurs de départ).
- c'est également le cas pour des affectations entre caractères ayant des code page différents.
- les affectations de valeurs numériques à des caractères ANSI devront être examinées de près, la même valeur numérique ne correspondant pas au même code point suivant la valeur de code page (exemple de l'euro)
5.7.2 - Surtypage Mentionnons que lorsque nous utilisons des surtypages, Delphi effectue aussi des CONVERSIONS. Cela a existé depuis Turbo Pascal. C'est un peu choquant, car le surtypage consiste normalement uniquement à
demander au Compilateur de considérer une zone mémoire avec le format que nous spécifions par le surtypage, et non le type de la déclaration. Voici un exemple ou nous surtypons un Integer par un tableau de 4 octets:
Type t_byte_array= Packed Array[0..3] Of Byte;
t_pt_byte_array= ^t_byte_array;
Procedure TForm1.surtypage_Click(Sender: TObject);
Var l_integer: Integer;
l_pt_byte_array: t_pt_byte_array;
l_result: String;
l_index: Integer;
Begin
l_integer:= $11223344;
display('@addr $'+ IntToHex(Integer(@l_integer), 4)+ ' value $'+ IntToHex(l_integer, 4));
l_pt_byte_array:= t_pt_byte_array(@l_integer);
l_result:= '@addr $'+ IntToHex(Integer(l_pt_byte_array), 4)+ ' value $';
For l_index:= 0 To 3 Do
l_result:= l_result+ ' '+ IntToHex(l_pt_byte_array^[l_index], 2);
display(l_result);
End; // surtypage_Click
|
qui fournit le résultat suivant: 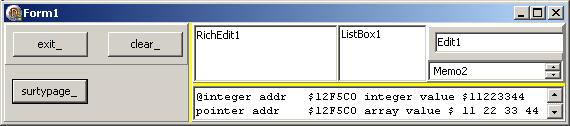 donc, nous avons bien demandé au compilateur de considérer les 4 octets de
l'entier comme un tableau de 4 octets (même adresse, même contenu, mais analysé avec un autre format)
5.7.3 - Surtypage / conversion de String Lorsque nous utilisons le nom de type UnicodeString pour surtyper une chaîne
Ansi, le compilateur effectuera une conversion. Le nom de type joue le même rôle qu'une fonction de conversion. Voici un exemple où nous créons une AnsiString, puis affichons le résultat surtypé par UnicodeString:
Procedure TForm1.string_cast_Click(Sender: TObject);
Var l_ansi_string: AnsiString; pbytes
Begin
l_ansi_string:= 'abc';
do_display(UnicodeString(l_ansi_string));
With t_pt_new_string_header(Integer(l_ansi_string)- 12)^ Do
display(IntToStr(m_code_page));
With t_pt_new_string_header(Integer(UnicodeString(l_ansi_string))- 12)^ Do
display(IntToStr(m_code_page));
End; // ansistring_Click
| qui fournit : 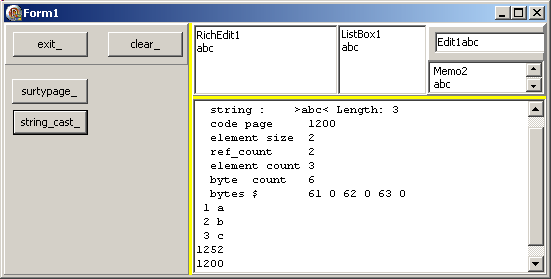
et qui démonter que notre AinsiString a bien été transformée en une autre structure, tant au point de vue taille que prologue (le code page).
En revanche, le surtypage par pChar et pAnsiChar se comportent comme un
"surtypage pur", sans conversion. Donc - nous pouvons surtyper une String par pChar, une AnsiString par pAnsiChar
- nous NE POUVONS PAS surtyper une String par pAnsiChar
(pAnsiChar(my_string)) fournit le premier caractère
- nous NE POUVONS PAS surtyper une AnsiString par pChar (la string considérera 2 caractères ANSI comme 1 caractère unicode !)
Voici un exemple de test pChar et String :
Function f_test_pchar(p_pchar: pChar; Var pv_pchar: pchar): pchar;
Var l_string, l_pv_string, l_result_string: String;
Begin
l_string:= String(p_pchar);
display(l_string);
l_pv_string:= 'pv '+ l_string;
display('param_v '+ String(l_pv_string));
pv_pchar:= pChar(l_pv_string);
l_result_string:= 'resu '+ l_string;
Result:= pChar(l_result_string);
End; // f_test_pchar
Procedure TForm1.pchar_Click(Sender: TObject);
Var l_string: String;
l_pchar, l_pv_pchar, l_result_pchar: pChar;
l_result_string: String;
Begin
l_string:= 'abc';
// OK l_result_pchar:= f_test_pchar(@l_string[1], l_pv_pchar);
l_result_pchar:= f_test_pchar(pChar(l_string), l_pv_pchar);
display(String(l_result_pchar)+ ' param_v '+ String(l_pv_pchar)+ '<');
display(String(f_test_pchar(pChar('abc'), l_pv_pchar))
+ ' param_v '+ String(l_pv_pchar)+ '<');
End; // pchar_Click
| dont voici le résultat : 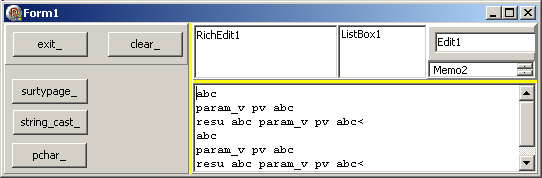 Et voici un exemple similaire avec des pAnsiChar:
Function f_test_p_ansi_char(p_p_ansi_char: pAnsiChar; Var pv_p_ansi_char: pAnsichar): pAnsichar;
Var l_string, l_pv_string, l_result_string: String;
l_pv_ansi_string, l_result_ansi_string: AnsiString;
Begin
l_string:= String(p_p_ansi_char);
display('param '+ l_string);
l_pv_string:= 'pv '+ l_string;
display('param_v '+ String(l_pv_string));
// NO 1stChar pv_p_ansi_char:= pAnsiChar(l_pv_string);
l_pv_ansi_string:= 'pv '+ l_string;
pv_p_ansi_char:= pAnsiChar(l_pv_ansi_string);
l_result_string:= 'resu '+ l_string;
// NO 1st char Result:= pAnsiChar(l_result_string);
l_result_ansi_string:= 'resu '+ l_string;
Result:= pAnsiChar(l_result_ansi_string);
End; // f_test_p_ansi_char
Procedure TForm1.p_ansi_char_call_Click(Sender: TObject);
Var l_string: String;
l_p_ansi_char, l_pv_p_ansi_char, l_result_p_ansi_char: pAnsiChar;
l_result_string: String;
Begin
l_result_p_ansi_char:= f_test_p_ansi_char('abc', l_pv_p_ansi_char);
display(String(l_result_p_ansi_char)+ ' param_v '+ String(l_pv_p_ansi_char)+ '<');
display(String(f_test_p_ansi_char('abc', l_pv_p_ansi_char))+ ' param_v '+ String(l_pv_p_ansi_char)+ '<');
End; // p_ansi_char_call_Click
| qui fournit : 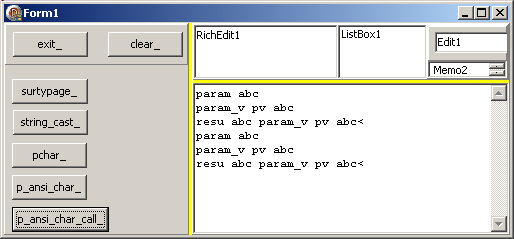
Par conséquent, nous devrons donc vérifier si le projet à modifier contient des surtypages, et qu'ils sont corrects en unicode.
5.7.4 - Surtypages obscurs
Les surtypages restent à utiliser uniquement dans les cas où ils ne peuvent être évités. Il faut éviter : - la lecture, ou pire, la modification des prologues des AnsiString ou
UnicodeString (les 8 ou 12 octets précédent le pointeur de la variable chaîne). Nous n'avons affiché le contenu de ces prologues dans cet article que pour illustrer le codage actuel. Comme mentionné, les prologues ont été
changée depuis Delphi 2009, et pourront l'être à l'avenir. Il faut utiliser les fonctions de la librairie (Length, SetLength, StringRefCount, StringCodePage, StringElementSize etc).
- les surtypages obscurs tels que AnsiString(Pointer(xxx))
- les surtypages de pointeurs de caractères contre nature tels que pChar(mon_AnsiString) ou pAnsiChar(mon_UnicodeString)
5.8 - Appels de DLL Fondamentallement les .DLL sont des modules C. Nous pouvons utiliser les types compatibles C, tels que les entiers, les Doubles, le pChar ou les pAnsiChar.
Les String, avant ou après Delphi 2009, sont des structures Delphi, et nécessitent un gestionnaire de mémoire spécifique. Celui ci peut être importé dans le .DLL en important, comme première unité de la Library, de .DPR et de
l'unité qui utilise la DLL l'unité SHAREMEM. Voici une .DLL que nous allons compiler avec Delphi 6:
Library d_d6_echo;
Uses ShareMem, SysUtils;
Function f_d6_echo(p_string_z: pChar): pChar; Stdcall;
Var l_string: String;
Begin
l_string:= p_string_z;
l_string:= IntToStr(Length(l_string))+ ' echo '+ l_string;
l_string:= l_string+ ' '+ IntToStr(Length(l_string));
Result:= pChar(l_string);
End; // f_echo_d6
Function f_d6_string_echo(p_string: String): String; Stdcall;
Var l_string: String;
Begin
l_string:= IntToStr(Length(p_string))+ ' echo '+ p_string;
Result:= l_string+ ' '+ IntToStr(Length(l_string));
End; // f_d6_string_echo
Exports f_d6_echo, f_d6_string_echo;
End |
Appeler la .DLL Delphi 6 depuis Delphi 2010 ne pose aucun problème pour la fonction utilisant des pChar:
Function f_d6_echo(p_string_z: pAnsiChar): pAnsiChar; Stdcall;
External 'd_d6_echo.dll';
Procedure TForm1.static_import_pchar_Click(Sender: TObject);
Var l_ansi_sring: AnsiString;
l_string, l_result: String;
l_p_ansichar, l_pt_result: pAnsiChar;
Begin
display(f_d6_echo('abc'));
l_ansi_sring:= 'abc';
// NO incompatible l_p_ansichar:= pAnsiString(l_ansi_sring);
l_p_ansichar:= @l_ansi_sring[1];
l_pt_result:= f_d6_echo(l_p_ansichar);
l_result:= String(l_pt_result);
display(l_result);
End; // static_import_Click
|
En revanche, utiliser la fonction avec des paramètres, des paramètres variable ou des résultat de fonction String ne semble pas possible - les allocateurs mémoire ne sont pas les mêmes: la .DLL Delphi 6 va gérer les
String de façon différentes de l'appplication Delphi 2010
- cela va se traduire par des violations d'accès
- pour les fonctions retournant une String, une des causes possibles est que
dès que l'appel de la fonction est terminé, le résultat de la fonction est libéré, mais pas de façon cohérente. Utiliser dans la .DLL une globale qui maintient une référence vers le résultat ne donne pas un résultat tout à fait correct
Maintenant, si nous compilons la .DLL avec Delphi 2010, la fonction qui utilise et retourne une String fonctionne correctement
En résumé - les .DLL utilisant des pChar ou pAnsiChar sont facilement adaptables. Pour
ceux qui souhaitent traduire des librairies C, soulignons que les pChar "C" sont toujours des pointeurs de caractères d'un octet.
- les .DLL utilisant des String
- peuvent être adaptées après recompilation en Delphi 2009 ou suivant
- ne seront pas directement adaptables si seul le binaire de la .DLL compilé avec une version antérieure à Delphi 2009 existe.
5.9 - Bases de données Avant Delphi 2009, - les unités concernant les bases de données utilisaient beaucoup de WideString.
- tStringField.Value était défini comme une String (donc AnsiString)
- tWideStringField.Value était défini comme WideString
- les tBookmarkStr étaient gérés comme des String (pour bénéficier de la libération automatique)
- le tampon des données utilisait des pChar
Depuis Delphi 2009 - la majorité des WideString ont été basculées en String.
- toutefois
- dbEdit.Datafield (le nom de la colonne) est encore WideString
- tStringField.Value est défini comme AnsiString
- tWideStringField.Value est défini comme UnicodeString
- les tBookMarkStr doivent être remplacés par des tBookMark
- l'accès au tampon doit se faire par une variable de type tRecordBuffer (défini comme un pByte)
6 - Stratégies de migration Globalement, nous pouvons - détecter les lignes posant problème
- effectuer des essais réduits, en cas de doute
- déterminer une stratégie
- utiliser des outils de transformation automatique
- vérifier que les modifications sont correctes
- vérifier la performance, et optimiser au besoin (profilage)
6.1 - Evaluation de la situation
La présentation ci-dessus devrait permettre de se faire une idée des zones qui peuvent nécessiter des adaptation, et évaluer l'ampleur de ces modifications. Il est possible d'utiliser des utilitaires qui détectent les zones à modifier
et en présente la list. Pour cela, il suffit d'analyser le source et recherchent - les pChar
- les Set of Char
- les utilisations de primitives système (Move, FillChar ...)
- caractères littéraux dépassant 128
- surtypages en tous genres
- appels de .DLL externes dont nous n'avons pas les sources
Un tel utilitaire d'analyse des sources est
disponible sur Code Central. En fait il utiliser le Parser de Martin Waldenburg pour rechercher les mots cités ci dessus. Mais cet utilitaire ne fournit pas de diagnostic Nous utilisons un analyseur dérivé de notre analyseur lexical Delphi (non
publié) à qui nous avons ajoutés des couches logiques pour détecter les problèmes potentiels
6.2 - Essais réduits Une fois que le bilan a été établi, il faut s'assurer que nous savons comment
traiter chaque cas. En cas de doute, le mieux est de faire des essais sur des petits programmes de test. A ce niveau, il est recommandé de brancher tous les avertissements. Nous modifions ces avertissements par "projet | options | compilateur |
avertissements":  Tiré de l'aide, voici Les warnings concernant les chaînes de caractères:
- 1057: Transtypage de chaîne implicite de '%s' en '%s' (IMPLICIT_STRING_CAST)
Emis quand le compilateur détecte un cas où il doit convertir implicitement un AnsiString (ou AnsiChar) en un format Unicode (un UnicodeString ou un
WideString). (REMARQUE : Cet avertissement sera éventuellement activé par défaut).
- 1058: Transtypage de chaîne implicite avec perte de données potentielle de '%s' en '%s' (IMPLICIT_STRING_CAST_LOSS)
Emis quand le compilateur détecte un cas où il doit convertir implicitement un format Unicode (un UnicodeString ou un WideString) en un AnsiString (ou AnsiChar). C'est une conversion à perte potentielle puisqu'il est possible
que certains caractères de la chaîne ne puissent pas être représentés dans la page de code dans laquelle la chaîne est convertie. (REMARQUE : Cet avertissement sera éventuellement activé par défaut).
- 1059: Transtypage de chaîne explicite de '%s' en '%s' (EXPLICIT_STRING_CAST)
Emis quand le compilateur détecte un cas où le programmeur transtype explicitement un AnsiString (ou AnsiChar) en un format Unicode
(UnicodeString ou WideString). (REMARQUE : Cet avertissement sera toujours désactivé par défaut et ne doit être utilisé que pour localiser des problèmes potentiels).
- 1060: Transtypage de chaîne explicite avec perte de données potentielle de
'%s' en '%s' (EXPLICIT_STRING_CAST_LOSS)
Emis quand le compilateur détecte un cas où le programmeur transtype explicitement un format Unicode (UnicodeString ou WideString) en AnsiString
(ou AnsiChar). C'est une conversion à perte potentielle puisqu'il est possible que certains caractères de la chaîne ne puissent pas être représentés dans la page de code dans laquelle la chaîne est convertie.
(REMARQUE : Cet avertissement sera toujours désactivé par défaut et ne doit être utilisé que pour localiser des problèmes potentiels). - W1041: Erreur à la conversion de caractère Unicode dans le jeu de caractères
de la locale. Chaîne tronquée. Votre variable d'environnement LANG est-elle définie correctement ? (Delphi)
- W1042: Erreur à la conversion de la chaîne locale '%s' en Unicode. Chaîne
tronquée. Votre variable d'environnement LANG est-elle définie correctement ? (Delphi)
- W1044 : Transtypage suspect de %s en %s (Delphi)
- W1050: WideChar réduit en byte char dans les expressions ensemble (Delphi)
- W1062 : La réduction de la constante chaîne étendue donnée génère une perte d'information (Delphi)
- W1063 : L'agrandissement de la constante AnsiChar donnée en WideChar génère une perte d'information (Delphi)
- W1064 : L'agrandissement de la constante AnsiString donnée génère une perte d'information (Delphi)
6.3 - Stratégie 6.3.1 - Tout AnsiString
Pour préserver le status quo, il est tentant de tout basculer en AnsiString et AnsiChar. Il est même possible d'utiliser un outil qui le fait automatiquement. Toutefois
- les API Windows sont actuellement en WideString, et nos appels provoqueront donc de nombreuses conversions
6.3.2 - Gérer les points d'entrée Stratégie diamétralement opposée, nous pouvons décider de tout gérer en
Unicode. Si nous fournissons des composants ou des unités à des utilisateurs qui souhaitent rester en ansi, nous pouvons ajouter des interfaces où les chaînes sont en ansi. Un peu la mécanique utilisée par les unités telles que ANSISTRING.PAS de Delphi
Il faudra, de toutes les façons gérer en Ansi - la gestion .HTML et certains protocoles
- les appels des .DLL dont nous n'avons pas les sources, et qui utilisent des pChar C
6.3.3 - Stratégie Mixte
En général, ce sera une stratégie mixte qui sera adoptée, en fonction des traitements effectués par les unités
7 - Télécharger le code source Delphi
Vous pouvez télécharger les projets suivants: Ce .ZIP qui comprend:
- le .DPR, la forme principale, les formes annexes eventuelles
- les fichiers de paramètres (le schéma et le batch de création)
- dans chaque .ZIP, toutes les librairies nécessaires à chaque projet (chaque .ZIP est autonome)
Ces .ZIP, pour les projets en Delphi 6, contiennent des chemins RELATIFS. Par conséquent: - créez un répertoire n'importe où sur votre machine
- placez le .ZIP dans ce répertoire
- dézippez et les sous-répertoires nécessaires seront créés
- compilez et exécutez
Ces .ZIP ne modifient pas votre PC (pas de changement de la Base de Registre, de DLL ou autre). Pour supprimer le projet, effacez le répertoire.
La notation utilisée est la notation alsacienne qui consiste à préfixer les identificateurs par la zone de compilation: K_onstant, T_ype, G_lobal,
L_ocal, P_arametre, F_unction, C_lasse. Elle est présentée plus en détail dans l'article La
Notation Alsacienne
Comme d'habitude: - nous vous remercions de nous signaler toute erreur, inexactitude ou
problème de téléchargement en envoyant un e-mail à jcolibri@jcolibri.com. Les corrections qui en résulteront pourront aider les prochains lecteurs
- tous vos commentaires, remarques, questions, critiques, suggestion d'article, ou mentions d'autres sources sur le même sujet seront de même les bienvenus à jcolibri@jcolibri.com.
- plus simplement, vous pouvez taper (anonymement ou en fournissant votre e-mail pour une réponse) vos commentaires ci-dessus et nous les envoyer en cliquant "envoyer" :
- et si vous avez apprécié cet article, faites connaître notre site, ajoutez un lien dans vos listes de liens ou citez-nous dans vos
blogs ou réponses sur les messageries. C'est très simple: plus nous aurons de visiteurs et de références Google, plus nous écrirons d'articles.
8 - Glossaire Unicode
- code point : la valeur unique, sur 4 octet de chaque "caractère" unicode
- code unit : 2 octets utilisés par UTF-16. Certains caractères (composites, surrogates) utilisent plusieurs code units
- code page : le code qui définit comment sont utilisé les caractères 128..255 en ansi
- BMP : Basic Multilingual Plane : les caractères dont le code point est inférieur à 64 K
- BOM : Byte Order Mark : la signature placées au début des fichiers disque pour indiquer comment sont organisés les octets des caractères de ce fichier
- UTF_8 : une représentation des caractères Unicode pour laquelle les
caractères utilisent 1, 2 ou 4 octets
- UTF-16 : une représentation des caractères Unicode, pour laquelle les caractères utilisent un ou plusieurs "code units", qui sont des groupes de 2 octets
- UTF-32 : une représentation des caractères unicode, utilisant 4 octets pour chaque caractère
- surrogate : caractère UTF-16 utilisant 2 code units (2 fois 2 octets)
- composite : caractère UTF-16 assemblé à partir de plusieurs code units (le "e" et son "accent aigu"
9 - Références Unicode - The Absolute
Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) - Joel On Software - un présentation Unicode simple
- Msdn
- http://www.unicode.org/ _ The Unicode Consortium
-
ID: 27398, Unicode Statistics Tool - Anders Ohlsson - un analyseur de sources indiquant quelles unités utilisent String, Char etc
- Les warnings unicode :
ms-help://embarcadero.rs2010/rad/Messages_d'erreur_et_d'avertissement_(Delphi)_-_Index.html
ou
http://docwiki.embarcadero.com/RADStudio/en/Error_and_Warning_Messages_%28Delphi%29_Index
10 - L'auteur John COLIBRI est passionné par le développement Delphi et les applications de Bases de Données. Il a écrit de nombreux livres et articles, et partage son temps entre le développement de projets (nouveaux projets, maintenance, audit, migration BDE, migration Xe_n, refactoring) pour ses clients, le
conseil (composants, architecture, test) et la
formation. Son site contient des articles
avec code source, ainsi que le programme et le calendrier des stages de formation Delphi, base de données, programmation objet, Services Web, Tcp/Ip et
UML qu'il anime personellement tous les mois, à Paris, en province ou sur site client.
|